Среда SQL Server Management Studio имеет два основных назначения: администрирование серверов баз данных и управление объектами баз данных. Эти функции рассматриваются далее.
Администрирование серверов баз данных
Задачи администрирования, которые можно выполнять с помощью среды SQL Server Management Studio, включают, среди прочих, следующие:
регистрация серверов;
подключение к серверу;
создание новых групп серверов;
управление множественными серверами;
пуск и остановка серверов.
Эти задачи администрирования описываются в следующих подразделах.
Регистрация серверов
Среда SQL Server Management Studio отделяет деятельность по регистрации серверов от деятельности по исследованию баз данных и их объектов. (Действия этих обоих типов можно выполнять посредством обозревателя объектов.) Прежде чем можно использовать базы данных и объекты любого сервера, будь то локального или удаленного, его нужно зарегистрировать.
Сервер можно зарегистрировать при первом запуске среды SQL Server Management Studio или позже. Чтобы зарегистрировать сервер базы данных, щелкните правой кнопкой требуемый сервер в обозревателе объектов и в контекстном меню выберите пункт Register. Если панель обозревателя объектов скрыта, то откройте ее, выполнив команду меню View --> Object Explorer. Откроется диалоговое окно New Server Registration (Регистрация нового сервера), как это показано на рисунке ниже:
Выберите имя сервера, который нужно зарегистрировать, и тип проверки подлинности для этого сервера (т.е. проверка подлинности Windows или проверка подлинности SQL Server), после чего нажмите кнопку Save.
Подключение к серверу
Среда SQL Server Management Studio также разделяет задачи регистрации сервера и подключения к серверу. Это означает, что при регистрации сервера автоматического подключения этого сервера не происходит. Чтобы подключиться к зарегистрированному серверу, нужно щелкнуть правой кнопкой требуемый сервер в окне инспектора объектов и в появившемся контекстном меню выбрать пункт Connect (Подключиться).
Создание новой группы серверов
Чтобы создать новую группу серверов в панели зарегистрированных серверов, щелкните правой кнопкой узел Local Server Groups (Группы локальных серверов) в окне Registered Server и в контекстном меню выберите пункт New Server Group (Создание группы серверов). В открывшемся диалоговом окне New Server Group Properties (Свойства новой группа серверов) введите однозначное имя группы и, по выбору, ее описание.
Управление множественными серверами
Посредством обозревателя объектов среда SQL Server Management Studio позволяет администрировать множественные серверы баз данных (называемые экземплярами) на одном компьютере. Каждый экземпляр компонента Database Server имеет свой собственный набор объектов баз данных (системные и пользовательские базы данных), который не разделяется между экземплярами.
Для управления сервером и его конфигурацией щелкните правой кнопкой имя сервера в обозревателе объектов и в появившемся контекстном меню выберите пункт Properties (Свойства). Откроется диалоговое окно Server Properties (Свойства сервера), содержащее несколько страниц, таких как General (Общие), Security (Безопасность), Permissions (Разрешения) и т.п.
На странице General отображаются общие свойства сервера:

Страница Security содержит информацию о режиме аутентификации сервера и методе аудита входа. На странице Permissions воспроизводятся все учетные записи и роли, которые имеют доступ к серверу. В нижней части страницы отображаются все разрешения, которые можно предоставлять этим учетным записям и ролям.
Можно изменить имя сервера, присвоив ему новое имя. Для этого щелкните правой кнопкой требуемый сервер в окне обозревателя объектов и в контекстном меню выберите пункт Register. Теперь можно присвоить серверу новое имя и изменить его описание. Серверы не следует переименовывать без особой на это надобности, поскольку это может повлиять на другие серверы, которые ссылаются на них.
Запуск и останов серверов
Сервер Database Engine по умолчанию запускается автоматически при запуске операционной системы Windows. Чтобы запустить сервер с помощью среды SQL Server Management Studio, щелкните правой кнопкой требуемый сервер в инспекторе объектов и в контекстном меню выберите пункт Start (Запустить). Это меню также содержит пункты Stop (Остановить) и Pause (Приостановить) для выполнения соответствующих действий с сервером.
Управление базами данных посредством обозревателя объектов Object Explorer
Задачи администрирования, которые можно выполнять с помощью среды SQL Server Management Studio, включают:
создание баз данных, не прибегая к использованию языка Transact-SQL;
модифицирование баз данных, не прибегая к использованию языка Transact-SQL;
управление таблицами, не прибегая к использованию языка Transact-SQL;
создание и исполнение инструкций SQL (описывается в следующей статье).
Создание баз данных без использования T-SQL
Новую базу данных можно создать посредством обозревателя объектов Object Explorer . Как можно судить по его названию, обозреватель объектов также можно использовать для исследования объектов сервера. С панели этого инструмента можно просматривать все объекты сервера и управлять сервером и базами данных. Дерево иерархии объектов сервера содержит, среди прочих папок, папку Databases (Базы данных). Эта папка, в свою очередь, содержит несколько подпапок, включая папку для системных баз данных, и по папке для каждой базы данных, созданной пользователем.
Чтобы создать базу данных посредством обозревателя объектов, щелкните правой кнопкой узел Databases и выберите пункт меню New Database (Создать базу данных). В открывшемся диалоговом окне New Database в поле Database name введите имя новой базы данных, после чего нажмите кнопку ОК.

Каждая база данных обладает несколькими свойствами, такими как тип файла, начальный размер и т.п. Список страниц свойств базы данных расположен в левой панели диалогового окна New Database. Страница General (Общие) диалогового окна Database Properties содержит, среди прочего, такую информацию, как имя, владелец и параметры сортировки базы данных:

Свойства файлов данных определенной базы данных перечисляются на странице Files (Файлы) и содержат такую информацию, как имя и начальный размер файла, расположение базы данных, а также тип файла (например, primary). База данных может храниться в нескольких файлах. В SQL Server применяется динамическое управление дисковым пространством. Это означает, что можно сконфигурировать размер базы данных для автоматического увеличения и уменьшения по мере надобности.
Чтобы изменить свойство Autogrowth (Автоувеличение) на странице Files, в столбце Autogrowth нажмите значок троеточия (...) и внесите соответствующие изменения в диалоговом окне Change Autogrowth. Чтобы позволить автоматическое увеличение размера базы данных, нужно установить флажок Enable Autogrowth . Каждый раз, когда существующий размер файла недостаточен для хранения добавляемых данных, сервер автоматически запрашивает систему выделить файлу дополнительное дисковое пространство. Объем дополнительного дискового пространства (в процентах или мегабайтах) указывается в поле File Growth (Увеличение размера файла) в том же диалоговом окне. А в разделе Maximum File Size (Максимальный размер файла) можно или ограничить максимальный размер файла, установив переключатель Limited to (MB) (Ограничение (Мбайт)), или снять ограничения на размер, установив переключатель Unlimited (Без ограничений) (это настройка по умолчанию). При ограниченном размере файла нужно указать его допустимый максимальный размер.
На странице Filegroups (Файловые группы) диалогового окна Database Properties отображаются имена файловых групп, к которым принадлежит файл базы данных, раздел файловой группы (по умолчанию или заданный явно), а также операции, разрешенные для выполнения с файловой группой (чтение и запись или только чтение).
На странице Options (Параметры) диалогового окна Database Properties можно просмотреть и модифицировать все параметры уровня базы данных. Существуют следующие группы параметров: Automatic (Автоматически), Containment (Включение), Cursor (Курсор), Miscellaneous (Вспомогательные), Recovery (Восстановление), Service Broker (Компонент Service Broker) и State (Состояние). Группа State содержит, например, следующие четыре параметра:
Database Read-Only (База данных доступна только для чтения)Позволяет установить доступ к базе данных полный доступ или доступ только для чтения. В последнем случае пользователи не могут модифицировать данные. Значение по умолчанию этого параметра - False.
Restrict Access (Ограничение доступа)Устанавливает количество пользователей, которые могут одновременно использовать базу данных. Значение по умолчанию - MULTI_USER.
Database State (Состояние базы данных)Описывает состояние базы данных. Значение по умолчанию этого параметра - Normal.
Encryption Enabled (Шифрование включено)Определяет режим шифрования базы данных. Значение по умолчанию этого параметра - False.
На странице Extended Properties (Расширенные свойства) отображаются дополнительные свойства текущей базы данных. На этой странице можно удалять существующие свойства и добавлять новые.
На странице Permissions (Разрешения) отображаются все пользователи, роли и соответствующие разрешения.
Остальные страницы Change Tracking (Отслеживание изменений), Mirroring (Зеркальное отображение) и Transaction Log Shipping (Доставка журналов транзакций) описывают возможности, связанные с доступностью данных.
Модифицирование баз данных
С помощью обозревателя объектов можно модифицировать существующие базы данных, изменяя файлы и файловые группы базы данных. Чтобы добавить новые файлы в базу данных, щелкните правой кнопкой требуемую базу данных и в контекстном меню выберите пункт Properties. В открывшемся диалоговом окне Database Properties выберите страницу Files и нажмите кнопку Add, расположенную внизу раздела Database files. В раздел будет добавлена новая строка, в поле Logical Name которой следует ввести имя добавляемого файла базы данных, а в других полях задать необходимые свойства этого файла. Также можно добавить и вторичную файловую группу для базы данных, выбрав страницу Filegroups (Файловые группы) и нажав кнопку Add.
Упомянутые ранее свойства базы данных может модифицировать только системный администратор или владелец базы данных.
Чтобы удалить базы данных с помощью обозревателя объектов, щелкните правой кнопкой имя требуемой базы данных и в открывшемся контекстном меню выберите пункт Delete (Удалить).
Управление таблицами
Следующей задачей после создания базы данных является создание всех необходимых таблиц. Подобно созданию базы данных, таблицы в ней также можно создать либо с помощью языка Transact-SQL, либо посредством обозревателя объектов. Как и в случае с созданием базы данных, здесь мы рассмотрим создание таблиц только с помощью обозревателя объектов.
Для практики создания таблиц, в базе данных SampleDb создадим таблицу Department. Чтобы создать таблицу базы данных с помощью обозревателя объектов, разверните в нем узел Databases, а потом узел требуемой базы данных, щелкните правой кнопкой папку Tables и в открывшемся контекстном меню выберите пункт New Table. В верхней части с правой стороны окна средства Management Studio откроется окно для создания столбцов новой таблицы. Введите имена столбцов таблицы, их типы данных и разрешение значений null для каждого столбца, как это показано в правой верхней панели на рисунке ниже:

Чтобы выбрать для столбца один из поддерживаемых системой типов данных, в столбце Data Type (Тип данных) выберите, а затем нажмите направленный вниз треугольник у правого края поля (этот треугольник появляется после того, как будет выбрана ячейка). В результате в открывшемся раскрывающемся списке выберите требуемый тип данных для столбца.
Тип данных существующего столбца можно изменить на вкладке Column Properties (Свойства столбца) (нижняя панель на рисунке). Для одних типов данных, таких как char, требуется указать длину в строке Length, а для других, таких как decimal, на вкладке Column Properties требуется указать масштаб и точность в соответствующих строках Scale (Масштаб) и Precision (Точность). Для некоторых других, таких как int, не требуется указывать ни одно из этих свойств. (Недействительные значения для конкретного типа данных выделены затененным шрифтом в списке всех возможных свойств столбца.)
Чтобы разрешить значения null для данного столбца, следует установить для него соответствующий флажок поля. Также, если для столбца требуется значение по умолчанию, его следует ввести в строку Default Value or Binding (Значение по умолчанию или привязка) панели Column Properties. Значение по умолчанию присваивается ячейке столбца автоматически, если для нее явно не введено значение.
Столбец Number является первичным ключом таблицы Department. Чтобы сделать столбец первичным ключом таблицы, щелкните его правой кнопкой и в контекстном меню выберите пункт Set Primary Key (Задать первичный ключ).
Завершив все работы по созданию таблицы, щелкните крестик вкладки конструктора таблиц. Откроется диалоговое окно с запросом, сохранить ли сделанные изменения. Нажмите кнопку Yes, после чего откроется диалоговое окно Choose Name (Выбор имени) с запросом ввести имя таблицы. Введите требуемое имя таблицы и нажмите кнопку OK. Таблица будет сохранена под указанным именем. Чтобы отобразить новую таблицу в иерархии базы данных, в панели инструментов обозревателя объектов щелкните значок Renew (Обновить).
Для просмотра и изменения свойств существующей таблицы разверните узел базы данных, содержащей требуемую таблицу, разверните узел Tables в этой базе данных и щелкните правой кнопкой требуемую таблицу, а затем в контекстном меню выберите пункт Properties. В результате для данной таблицы откроется диалоговое окно Table Properties. Для примера, на рисунке ниже показано диалоговое окно Table Properties на вкладке General для таблицы Employee базы данных SampleDb.

Чтобы переименовать таблицу, в папке Tables щелкните ее правой кнопкой в списке таблиц и в контекстном меню выберите пункт Rename. А чтобы удалить таблицу, щелкните ее правой кнопкой и выберите пункт Delete.
Создав все четыре таблицы базы данных SampleDb (Employee, Department, Project и Works_on - подробную структуру таблиц вы можете найти в исходниках), можно использовать еще одну возможность среды SQL Server Management Studio, чтобы отобразить диаграмму типа "сущность - отношение" - диаграмму (ER) (entity-relationship) этой базы данных. (Процесс преобразования таблиц базы данных в диаграмму "сущность - отношение" (ER) называется обратным проектированием.)
Чтобы создать диаграмму ER для базы данных SampleDb, щелкните правой кнопкой ее подпапку Database Diagrams (Диаграммы баз данных) и в контекстном меню выберите пункт New Database Diagram (Создать диаграмму базы данных). Если откроется диалоговое окно, в котором спрашивается, создавать ли вспомогательные объекты, выберите ответ Yes.
После этого откроется диалоговое окно Add Table, в котором нужно выбрать таблицы для добавления в диаграмму. Добавив все необходимые таблицы (в данном случае все четыре), нажмите кнопку Close, и мастер создаст диаграмму, подобную показанной на рисунке ниже:

На рисунке показана только промежуточная, а не конечная диаграмма ER базы данных SampleDb, поскольку, хотя на ней и показаны все четыре таблицы с их столбцами (и соответствующими первичными ключами), на ней все же отсутствуют отношения между таблицами. Отношение между двумя таблицами основывается на первичном ключе одной из таблиц и возможным соответствующим столбцом (или столбцами) другой таблицы.
Между таблицами базы данных SampleDb существует три отношения. Таблица Department имеет отношение типа 1:N с таблицей Employee, поскольку каждому значению первичного ключа таблицы Department (столбец Number) соответствует одно или более значений столбца DepartmentNumber таблицы Employee (в одном отделе может работать несколько сотрудников).
Аналогично существует отношение между таблицами Employee и Works_on, поскольку только значения, которые присутствуют в столбце первичного ключа таблицы Employee (Id) также имеются в столбце EmpId таблицы Works_on. Третье отношение существует между таблицами Project и Works_on, т.к. только значения, которые присутствуют в первичном ключе таблицы Project (Number) также присутствуют в столбце ProjectNumber таблицы Works_on.
Чтобы создать эти три отношения, диаграмму ER нужно реконструировать, указав для каждой таблицы столбцы, которые соответствуют ключевым столбцам других таблиц. Такой столбец называется внешним ключом (foreign key) . Чтобы увидеть, как это делается, определим столбец DepartmentNumber таблицы Employee, как внешний ключ таблицы Department. Для этого выполним следующие действия:

Подобным образом создаются и другие два отношения. На рисунке ниже показана диаграмма ER, отображающая все три отношения между таблицами базы данных SampleDb:

В среде SQL Server предусмотрен ряд различных управляющих конструкций, без которых невозможно написание эффективных алгоритмов.
Группировка двух и более команд в единый блок осуществляется с использованием ключевых слов BEGIN и END:
<блок_операторов>::=
Сгруппированные команды воспринимаются интерпретатором SQL как одна команда. Подобная группировка требуется для конструкций поливариантных ветвлений, условных и циклических конструкций. Блоки BEGIN...END могут быть вложенными.
Некоторые команды SQL не должны выполняться вместе с другими командами (речь идет о командах резервного копирования, изменения структуры таблиц, хранимых процедур и им подобных), поэтому их совместное включение в конструкцию BEGIN...END не допускается.
Нередко определенная часть программы должна выполняться только при реализации некоторого логического условия. Синтаксис условного оператора показан ниже:
<условный_оператор>::=
IF лог_выражение
{ sql_оператор | блок_операторов }
{sql_оператор | блок_операторов } ]
Циклы организуются с помощью следующей конструкции:
<оператор_цикла>::=
WHILE лог_выражение
{ sql_оператор | блок_операторов }
{ sql_оператор | блок_операторов }
Цикл можно принудительно остановить, если в его теле выполнить команду BREAK. Если же нужно начать цикл заново, не дожидаясь выполнения всех команд в теле, необходимо выполнить команду CONTINUE.
Для замены множества одиночных или вложенных условных операторов используется следующая конструкция:
<оператор_поливариантных_ветвлений>::=
CASE входное_значение
WHEN {значение_для_сравнения |
лог_выражение } THEN
вых_выражение [,...n]
[ ELSE иначе_вых_выражение ]
Если входное значение и значение для сравнения совпадают, то конструкция возвращает выходное значение. Если же значение входного параметра не найдено ни в одной из строк WHEN...THEN, то тогда будет возвращено значение, указанное после ключевого слова ELSE.
Основные объекты структуры базы данных SQL-сервера
Рассмотрим логическую структуру базы данных.
Логическая структура определяет структуру таблиц, взаимоотношения между ними, список пользователей, хранимые процедуры, правила, умолчания и другие объекты базы данных.
Логически данные в SQL Server организованы в виде объектов. К основным объектам базы данных SQL Server относятся следующие объекты.
Краткий обзор основных объектов баз данных.
Таблицы
Все данные в SQL содержатся в объектах, называемых таблицами . Таблицы представляют собой совокупность каких-либо сведений об объектах, явлениях, процессах реального мира. Никакие другие объекты не хранят данные, но они могут обращаться к данным в таблице. Таблицы в SQL имеют такую же структуру, что и таблицы всех других СУБД и содержат:
· cтроки; каждая строка (или запись) представляет собой совокупность атрибутов (свойств) конкретного экземпляра объекта;
· cтолбцы; каждый столбец (поле) представляет собой атрибут или совокупность атрибутов. Поле строки является минимальным элементом таблицы. Каждый столбец в таблице имеет определенное имя, тип данных и размер.
Представления
Представлениями (просмотрами) называют виртуальные таблицы, содержимое которых определяется запросом. Подобно реальным таблицам, представления содержат именованные столбцы и строки с данными. Для конечных пользователей представление выглядит как таблица, но в действительности оно не содержит данных, а лишь представляет данные, расположенные в одной или нескольких таблицах. Информация, которую видит пользователь через представление, не сохраняется в базе данных как самостоятельный объект.
Хранимые процедуры
Хранимые процедуры представляют собой группу команд SQL, объединенных в один модуль. Такая группа команд компилируется и выполняется как единое целое.
Триггеры
Триггерами называется специальный класс хранимых процедур, автоматически запускаемых при добавлении, изменении или удалении данных из таблицы.
Функции
Функции в языках программирования – это конструкции, содержащие часто исполняемый код. Функция выполняет какие-либо действия надданными и возвращает некоторое значение.
Индексы
Индекс – структура, связанная с таблицей или представлением и предназначенная для ускорения поиска информации в них. Индекс определяется для одного или нескольких столбцов, называемых индексированными столбцами. Он содержит отсортированные значения индексированного столбца или столбцов со ссылками на соответствующую строку исходной таблицы или представления. Повышение производительности достигается за счет сортировки данных. Использование индексов может существенно повысить производительность поиска, однако для хранения индексов необходимо дополнительное пространство в базе данных.
©2015-2019 сайт
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2016-08-08
Порой так хочется привести свои мысли в порядок, разложить их по полочкам. А еще лучше в алфавитной и тематической последовательности, чтобы, наконец, наступила ясность мышления. Теперь представьте, какой бы хаос творился в «электронных мозгах » любого компьютера без четкой структуризации всех данных и Microsoft SQL Server :
MS SQL Server
Данный программный продукт представляет собой систему управления базами данных (СУБД ) реляционного типа, разработанную корпорацией Microsoft . Для манипуляции данными используется специально разработанный язык Transact-SQL . Команды языка для выборки и модификации базы данных построены на основе структурированных запросов:

Реляционные базы данных построены на взаимосвязи всех структурных элементов, в том числе и за счет их вложенности. Реляционные базы данных имеют встроенную поддержку наиболее распространенных типов данных. Благодаря этому в SQL Server интегрирована поддержка программного структурирования данных с помощью триггеров и хранимых процедур.
Обзор возможностей MS SQL Server

СУБД является частью длинной цепочки специализированного программного обеспечения, которое корпорация Microsoft создала для разработчиков. А это значит, что все звенья этой цепи (приложения ) глубоко интегрированы между собой.
То есть их инструментарий легко взаимодействует между собой, что во многом упрощает процесс разработки и написания программного кода. Примером такой взаимосвязи является среда программирования MS Visual Studio . В ее инсталляционный пакет уже входит SQL Server Express Edition .
Конечно, это не единственная популярная СУБД на мировом рынке. Но именно она является более приемлемой для компьютеров, работающих под управлением Windows, за счет своей направленности именно на эту операционную систему. И не только из-за этого.
Преимущества MS SQL Server :
- Обладает высокой степенью производительности и отказоустойчивости;
- Является многопользовательской СУБД
и работает по принципу «клиент-сервер
»;
Клиентская часть системы поддерживает создание пользовательских запросов и их отправку для обработки на сервер.
- Тесная интеграция с операционной системой Windows ;
- Поддержка удаленных подключений;
- Поддержка популярных типов данных, а также возможность создания триггеров и хранимых процедур;
- Встроенная поддержка ролей пользователей;
- Расширенная функция резервного копирования баз данных;
- Высокая степень защищенности;
- Каждый выпуск включает в себя несколько специализированных редакций.
Эволюция SQL Server
Особенности этой популярной СУБД легче всего прослеживаются при рассмотрении истории эволюции всех ее версий. Более подробно мы остановимся лишь на тех выпусках, в которые разработчики вносили весомые и кардинальные изменения:
- Microsoft SQL Server 1.0 – вышел еще в 1990 году. Уже тогда эксперты отмечали высокую скорость обработки данных, демонстрируемую даже при максимальной нагрузке в многопользовательском режиме работы;
- SQL Server 6.0 – вышел в 1995 году. В этой версии впервые в мире была реализована поддержка курсоров и репликации данных;
- SQL Server 2000 – в этой версии сервер получил полностью новый движок. Большая часть изменений коснулась лишь пользовательской стороны приложения;
- SQL Server 2005 – увеличилась масштабируемость СУБД , во многом упростился процесс управления и администрирования. Был внедрен новый API для поддержки программной платформы .NET ;
- Последующие выпуски – были направлены на развитие взаимодействия СУБД на уровне облачных технологий и средств бизнес-аналитики.
В базовый комплект системы входит несколько утилит для настройки SQL Server . К ним относятся:

Диспетчер конфигурации. Позволяет управлять всеми сетевыми настройками и службами сервера базы данных. Используется для настройки SQL Server внутри сети.
- SQL Server Error and Usage Reporting :

Утилита служит для настройки отправки отчетов об ошибках в службу поддержки Microsoft .

Используется для оптимизации работы сервера базы данных. То есть вы можете настроить функционирование SQL Server под свои нужды, включив или отключив определенные возможности и компоненты СУБД .
Набор утилит, входящих в Microsoft SQL Server , может отличаться в зависимости от версии и редакции программного пакета. Например, в версии 2008 года вы не найдете SQL Server Surface Area Configuration .
Запуск Microsoft SQL Server
Для примера будет использована версия сервера баз данных выпуска 2005 года. Запуск сервера можно произвести несколькими способами:
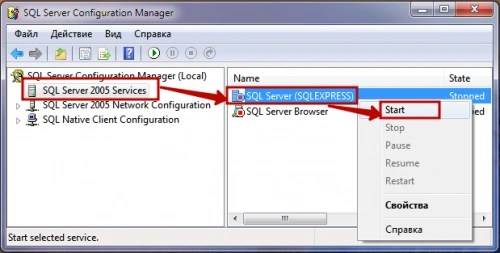
- Через утилиту SQL Server Configuration Manager . В окне приложения слева выбираем «SQL Server 2005 Services », а справа — нужный нам экземпляр сервера БД . Отмечаем его и в подменю правой кнопки мыши выбираем «Start ».
- С помощью среды SQL Server Management Studio Express . Она не входит в инсталляционный пакет редакции Express . Поэтому ее нужно скачивать отдельно с официального сайта Microsoft .
Для запуска сервера баз данных запускаем приложение. В диалоговом окне «Соединение с сервером » в поле «Имя сервера » выбираем нужный нам экземпляр. В поле «Проверка подлинности » оставляем значение «Проверка подлинности Windows ». И нажимаем на кнопку «Соединить »:

Основы администрирования SQL Server
Перед тем, как запустить MS SQL Server , нужно кратко ознакомиться с основными возможностями его настройки и администрирования. Начнем с более детального обзора нескольких утилит из состава СУБД :
- SQL Server Surface Area Configuration – сюда следует обращаться, если нужно включить или отключить какую-либо возможность сервера баз данных. Внизу окна находятся два пункта: первый отвечает за сетевые параметры, а во втором можно активировать выключенную по умолчанию службу или функцию. Например, включить интеграцию с платформой .NET через запросы T-SQL :
Если вы уже когда-либо писали схемы блокировок на других языках баз данных для преодоления недостатка блокировок (как я), то у вас могло остаться чувство, что обязательно нужно самому заниматься блокировками. Позвольте вас заверить, что диспетчеру блокировок можно полностью доверять. Тем не менее SQL Server предлагает несколько методов управления блокировками, о которых мы детально поговорим в этом разделе.
Не применяйте параметры блокировки и не изменяйте уровни изоляции случайным образом - доверьте менеджеру блокировок SQL Server выполнять балансировку конкуренции и целостности транзакций. Только если вы абсолютно уверены, что схема базы данных хорошо настроена, а программный код буквально отшлифован, можете слегка подкорректировать работу диспетчера блокировок, чтобы решить конкретную проблему. В некоторых случаях настройка запросов select на отсутствие блокировок способна решить большинство проблем.
Установка уровня изоляции подключения
Уровень изоляции определяет продолжительность общей или эксклюзивной блокировки подключения. Установка уровня изоляции оказывает влияние на все запросы и все таблицы, используемые на протяжении всего подключения или до явной замены одного уровня изоляции другим. В следующем примере устанавливается более плотная изоляция, чем задана по умолчанию, и предотвращаются неповторяющиеся чтения:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ Допустимыми уровнями изоляции являются:
Read uncommited ? serializable
Read commited ? snapshot
Repeatable read
Текущий уровень изоляции можно проверить с помощью команды проверки целостности базы данных (DBCC):
DBCC USEROPTIONS
Результаты будут следующими (сокращенно):
Set Option Value
isolation level repeatable read
Уровни изоляции могут быть также установлены на уровне запроса или таблицы с помощью параметров блокировки.
Использование изоляции уровня снимков базы данных
Существуют два варианта уровня изоляции снимков базы данных: snapshot и read commited snapshot. Изоляция snapshot работает подобно repeatable read, не занимаясь вопросами блокировки. Изоляция read commited snapshot имитирует установленный по умолчанию в SQL Server уровень read commited, так же снимая вопросы блокировки.
В то время как изоляцию транзакций, как правило, устанавливают на уровне подключений, изоляция snapshot должна конфигурироваться на уровне базы данных, поскольку она
эффективно отслеживает версионность строк в базе. Версионностъ строк - это технология, которая создает для обновления копии строк в базе данных TempDB. Кроме основной загрузки базы TempDB, версионность строк также добавляет 14-байтовый идентификатор строки.
Использование изоляции Snapshot
В следующем фрагменте включается уровень изоляции snapshot. Для корректировки базы данных и включения уровня изоляции snapshot к этой базе не должны быть установлены другие подключения.
ALTER DATABASE Aesop
SET ALLOW_SNAPSHOT_ISOLATION ON
| Для проверки того, включена ли в базе данных изоляция snapshot, выполните SVS следующий запрос: SELECT name, snapshot_isolation_state_desc FROM [ * sysdatabases.
Теперь первая транзакция начинает чтение и остается открытой (т.е. не подтвержденной): USE Aesop
BEGIN TRAN SELECT Title FROM FABLE WHERE FablelD = 2
Будет получен следующий результат:
В это время вторая транзакция начинает обновление той же строки, которая открыта первой транзакцией:
SET TRANSACTION ISOLATION LEVEL Snapshot;
BEGIN TRAN UPDATE Fable
SET Title = ‘Rocking with Snapshots’
WHERE FablelD = 2;
SELECT * FROM FABLE WHERE FablelD = 2
Результат следующий:
Rocking with Snapshots
He правда ли, удивительно? Вторая транзакция смогла обновить строку, даже несмотря на то, что первая транзакция осталась открытой. Вернемся к первой транзакции и увидим исходные данные:
SELECT Title FROM FABLE WHERE FablelD = 2
Результат следующий:
Если открыть третью и четвертую транзакции, то они увидят все то же исходное значение The Bald Knight:
Даже после того как вторая транзакция подтвердит изменения, первая будет по-прежнему видеть исходное значение, а все следующие транзакции - новое, Rocking with Snapshots.
Использование ИЗОЛЯЦИИ Read Commited Snapshot
Изоляция Read Commited Snapshot включается с помощью аналогичного синтаксиса:
ALTER DATABASE Aesop
SET READ_COMMITTED_SNAPSHOT ON
Подобно изоляции Snapshot, данный уровень для снятия вопросов блокировок также использует версионность строк. Если взять за основу пример, описанный в предыдущем разделе, то в данном случае первая транзакция увидит изменения, выполненные второй, как только они будут подтверждены.
Так как Read Commited является уровнем изоляции, принятым в SQL Server по умолчанию, требуется только установка параметров базы данных.
Разрешение конфликтов записи
Транзакции, записывающие данные при установленном уровне изоляции Snapshot, могут быть заблокированы предыдущими неподтвержденными транзакциями записи. Такая блокировка не заставит новую транзакцию ожидать - просто будет сгенерирована ошибка. Для обработки подобных ситуаций используйте выражение try. . . catch, выждите пару секунд и попробуйте повторить транзакцию снова.
Использование параметров блокировки
Параметры блокировки позволяют вносить временную коррекцию в статегию блокировки. В то время как уровень изоляции оказывает влияние на подключение в целом, параметры блокировки специфичны для каждой таблицы в конкретном запросе (табл. 51.5). Параметр WITH (параметр_блокировки) помещается после имени таблицы в предложении FROM запроса. Для каждой таблицы можно задать несколько параметров, разделяя их запятыми.
|
Таблица 51.5. Параметры блокировки |
Параметр блокировки |
Описание |
Уровень изоляции. He устанавливает и не удерживает блокировку. Равносилен отсутствию блокировок |
Уровень изоляции, установленный для транзакций по умолчанию |
Уровень изоляции. Удерживает общую и эксклюзивную блокировки до момента подтверждения транзакции |
Уровень изоляции. Удерживает общую блокировку до завершения транзакции |
Пропуск заблокированных строк вместо ожидания |
Включение блокировки на уровне строк вместо уровня страницы, экстента или таблицы |
Включение блокировки на уровне страниц вместо уровня таблицы |
Автоматическая эскалация блокировок уровня строк, страниц и экстента до гранулярности уровня таблицы |
Параметр блокировки |
Описание |
Неприменение и неудержание блокировок. То же, что и ReadUnCommited |
Включение эксклюзивной блокировки таблицы. Запрет другим транзакциям работать с таблицей |
Удержание общей блокировки до подтверждения транзакции (аналогично Serializable) |
Использование блокировки обновления вместо общей и ее удержание. Блокировка других записей в данные между изначальными операциями чтения и записи |
Удержание эксклюзивной блокировки данных до подтверждения транзакции |
В следующем примере в предложении FROM инструкции UPDATE использован параметр блокировки, запрещающий диспетчеру эскалировать гранулярность блокировки:
USE OBXKites UPDATE Product
FROM Product WITH (RowLock)
SET ProductName = ProductName + ‘ Updated 1
Если запрос содержит подзапросы, не забывайте, что обращение к таблице каждого из запросов генерирует блокировку, которой можно управлять с помощью параметров.
Ограничения блокировок уровня индексов
Уровни изоляции и параметры блокировки применяются на уровне подключений и запросов. Единственным способом управления блокировками на уровне таблицы является ограничение гранулярности блокировок на основе конкретных индексов. С помощью системной хранимой процедуры sp_indexoption блокировки строк и/или страниц можно отключить для конкретного индекса, используя следующий синтаксис: sp_indexoption ‘имя_индекса 1 ,
AllowRowlocks или AllowPagelocks,
Это может пригодиться в ряде особых случаев. Если таблица часто вызывает ожидания по причине блокировок страниц, то установка для параметра allowpagelocks значения off установит блокировку на уровне строк. Уменьшенная гранулярность блокировок положительно скажется на конкуренции. К тому же, если таблица редко обновляется, но часто считывается, блокировки на уровне строк и страниц нежелательны; в этом случае оптимальным является уровень блокировки на уровне таблиц. Если обновления выполняются нечасто, то эксклюзивная блокировка таблиц не приведет к большим проблемам.
Хранимая процедура Sp_indexoption предназначена для тонкой настройки схемы данных; именно поэтому в ней используется блокировка на уровне индексов. Для ограничения блокировок по первичному ключу таблицы используйте sp_help имя_ та блицы, чтобы найти имя индекса первичного ключа.
Следующая команда конфигурирует таблицу ProductCategory как редко обновляемый классификатор. Вначале команда sp_help выводит имя индекса первичного ключа таблицы: sp_help ProductCategory
Результат (усеченный) таков:
index index index
name description keys
PK_____________ ProductCategory 79A814 03 nonclustered, ProductCategorylD
unique, primary key located on PRIMARY
Имея в наличии реальное имя первичного ключа, системная хранимая процедура может установить параметры блокировки индекса:
EXEC sp_indexoption
‘ProductCategory.РК__ ProductCategory_______ 7 9А814 03′,
‘AllowRowlocks’, FALSE EXEC sp_indexoption
‘ProductCategory.PK__ ProductCategory_______ 79A81403′,
‘AllowPagelocks’, FALSE
Управление временем ожидания блокировок
Если транзакция ожидает блокировку, то это ожидание будет продолжаться до тех пор, пока блокировка не станет возможной. По умолчанию не существует предела времени ожидания - чисто теоретически оно может длиться вечно.
К счастью, вы можете установить время ожидания блокировки с помощью параметра подключения set lock_timeout. Установите для этого параметра количество миллисекунд или, если хотите не ограничивать время, установите для него значение -1 (оно принято по умолчанию). Если для этого параметра установлено значение 0, то транзакция будет немедленно отклонена при наличии какой-либо блокировки. В этом случае приложение будет исключительно быстродействующим, но малоэффективным.
В следующем запросе время ожидания блокировки устанавливается в две секунды (2000 миллисекунд):
SET Lock_Timeout 2 00 0
Если транзакция выходит за пределы установленного предельного времени ожидания, то генерируется ошибка с номером 1222.
Настоятельно рекомендую устанавливать предельное время ожидания блокировки на уровне подключения. Эта величина выбирается в зависимости от обычной производительности базы данных. Я предпочитаю устанавливать пятисекундное время ожидания.
Оценка производительности конкуренции в базе данных
Очень легко создать базу данных, в которой не решаются вопросы соревнования блокировок и конкуренции при тестировании на группе пользователей. Реальный тест - это когда несколько сотен пользователей одновременно обновляют заказы.
Тестирование конкуренции нужно правильно организовать. На одном уровне он должен содержать одновременное использование множеством пользователей одной и той же конечной формы. Может оказаться полезной и программа.NET, которая постоянно имитирует
просмотр пользователем данных и их обновление. Хороший тест должен запускать 20 экземпляров сценария, который постоянно загружает базу данных, а затем дать возможность команде тестировщиков использовать приложение. Количество блокировок поможет увидеть монитор производительности, о котором говорилось в главе 49.
Многопользовательскую конкуренцию лучше тестировать в процессе разработки несколько раз. Как говорится в экзаменационном руководстве MCSE, “не допускайте, чтобы тест в реальных условиях был первым”.
Блокировки приложения
SQL Server использует очень сложную схему блокировок. Иногда процесс или ресурс, отличный от данных, требует блокировки. Например, может быть необходимо запускать процедуру, которая наносит вред, если другой пользователь запустил еще один экземпляр той же процедуры.
Несколько лет назад я написал программу разводки кабелей в проектах атомных электростанций. Когда геометрия предприятия была спроектирована и протестирована, инженеры вводили состав кабельного оборудования, его местоположение и типы используемых кабелей. После того как вводилось несколько кабелей, программа формировала маршрут их прокладки так, чтобы он оказался как можно более коротким. Процедура также учитывала вопросы безопасности кабельной проводки и разделяла несовместимые кабели. В то же время, если множество процедур прокладки запускалось одновременно, каждый экземпляр пытался маршрутизировать одни и те же кабели, в результате чего результат оказывался некорректным. Блокировка приложений стала отличным решением этой проблемы.
Блокировка приложений открывает целый мир блокировок SQL, предназначенных для использования в приложениях. Вместо использования данных в качестве блокируемого ресурса, блокировки приложений блокируют использование всех пользовательских ресурсов, объявленных в хранимой процедуре sp__GetAppLock.
Блокировка приложений может применяться в транзакциях; при этом может быть объявлен режим блокировки Shared, Update, Exclusive, IntentExclusice или IntentShared. Возвращаемое процедурой значение указывает, успешным ли было применение блокировки.
0. Блокировка установлена успешно.
1. Блокировка была установлена, когда другая процедура сняла свою блокировку.
999. Блокировка не была установлена по другой причине.
Хранимая процедура sp_ReleaseApLock снимает блокировку. В следующем примере продемонстрировано, как блокировка приложения может использоваться в пакете или процедуре: DECLARE @ShareOK INT EXEC @ShareOK = sp_GetAppLock
@Resource = ‘CableWorm’,
@LockMode = ‘Exclusive’
IF @ShareOK < 0
…Код обработки ошибки
… Программный код …
EXEC sp_ReleaseAppLock @Resource = ‘CableWorm’
Когда блокировки приложения просматриваются с помощью Management Studio или процедуры sp_Lock, они отображаются с типом АРР. В следующем листинге приведен сокращенный вывод процедуры sp_Lock, запущенной одновременно с приведенным выше кодом: spid dbid Objld Indld Type Resource Mode Status
57 8 0 0 APP Cabllf 94cl36 X GRANT
Следует обратить внимание на два небольших отличия в том, как блокировки приложения обрабатываются в SQL Server:
Взаимоблокировки не выявляются автоматически;
Если некоторая транзакция устанавливает блокировку несколько раз, она должна снять ее ровно такое же количество раз.
Взаимоблокировки
Взаимоблокировкой называют особую ситуацию, которая возникает только тогда, когда транзакции с множеством задач соревнуются за ресурсы друг друга. Например, первая транзакция установила блокировку ресурса А, и ей необходимо заблокировать ресурс Б, а в это же время вторая транзакция, заблокировавшая ресурс Б, нуждается в блокировке ресурса А.
Каждая из этих транзакций ожидает, пока другая снимет свою блокировку, и ни одна из них не может завершиться, пока этого не произойдет. Если не произойдет внешнего воздействия или одна из транзакций завершится по определенной причине (например, по времени ожидания), то эта ситуация может продолжаться до конца света.
Раньше взаимоблокировки представляли собой серьезную проблему, но теперь SQL Server позволяет успешно разрешить ее.
Создание взаимоблокировки
Проще всего создать ситуацию взаимоблокировки в SQL Server с помощью двух подключений в редакторе запросов утилиты Management Studio (рис. 51.12). Первая и вторая транзакции пытаются обновить одни и те же строки, однако в противоположном порядке. Используя третье окно для запуска процедуры pGetLocks, можно выполнять мониторинг блокировок.
1. Создайте в редакторе запросов второе окно.
2. Поместите код блока Шаг 2 во второе окно.
3. В первое окно поместите код блока Шаг 1 и нажмите клавишу
4. Во втором окне аналогично выполните код Шаг 2.
5. Вернитесь в первое окно и выполните код блока Шаг 3.
6. Через короткий промежуток времени SQL Server обнаружит взаимоблокировку и автоматически устранит ее.
Ниже приведен программный код примера.
– Транзакция 1 — Шаг 1 USE OBXKites BEGIN TRANSACTION UPDATE Contact
SET LastName = ‘Jorgenson’
WHERE ContactCode = 401′
Puc. 51.12. Создание ситуации взаимоблокировки в Management Studio с помощью двух подключений (их окна расположены вверху)
Теперь первая транзакция установила эксклюзивную блокировку на запись со значением 101 в поле ContactCode. Вторая транзакция установит эксклюзивную блокировку строки со значением 1001 в поле ProductCode, а затем попытается эксклюзивно заблокировать запись, уже заблокированную первой транзакцией (ContactCode=101).
– Транзакция 2 — Шаг 2 USE OBXKites BEGIN TRANSACTION UPDATE Product SET ProductName
= ‘DeadLock Repair Kit’
WHERE ProductCode = ‘1001’
SET FirstName = ‘Neals’
WHERE ContactCode = ‘101’
COMMIT TRANSACTION
Пока еще взаимоблокировки не существует, поскольку транзакция 2 ожидает завершения транзакции 1, но транзакция 1 пока еще не ожидает завершения транзакции 2. В этой ситуации, если транзакция 1 завершит свою работу и выполнит инструкцию COMMIT TRANSACTION, ресурс данных будет освобожден, и транзакция 2 благополучно получит возможность необходимой ей блокировки и продолжит свои действия.
Проблема возникает, когда транзакция 1 попытается обновить строку с ProductCode=l. Однако необходимую для этого эксклюзивную блокировку она не получит, поскольку эта запись заблокирована транзакцией 2:
– Транзакция 1 — Шаг 3 UPDATE Product SET ProductName
= ‘DeadLock Identification Tester’
WHERE ProductCode = ‘1001’
COMMIT TRANSACTION
Транзакция 1 вернет следующее текстовое сообщение об ошибке спустя пару секунд. Возникшую взаимоблокировку можно также увидеть в SQL Server Profiler (рис. 51.13):
Server: Msg 1205, Level 13,
State 50, Line 1 Transaction (Process ID 51) was
deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Транзакция 2 завершит свою работу, будто бы проблемы и не существовало:
(1 row(s) affected)
(1 row(s) affected)

Рис. 51.13. SQL Server Profiler позволяет выполнять мониторинг взаимоблокировок с помощью события Locks:Deadlock Graph и выявлять ресурс, вызвавший взаимоблокировку
Автоматическое выявление взаимоблокировок
Как было продемонстрировано в приведенном выше коде, SQL Server автоматически выявляет ситуацию взаимоблокировки, проверяя блокирующие процессы и откатывая транзакции,
выполнившие наименьший объем работы. SQL Server постоянно проверяет существование перекрестных блокировок. Задержка выявления взаимоблокировок может варьироваться от нуля до двух секунд (на практике дольше всего мне приходилось ожидать этого пять секунд).
Обработка взаимоблокировок
Когда происходит взаимоблокировка, подключение, выбранное в качестве “жертвы” взаимоблокировки, должно повторить свою транзакцию. Так как работа должна быть переделана, хорошо, что откатывается именно та транзакция, которая успела выполнить наименьший объем работы, - именно она будет повторена сначала.
Ошибка с кодом 12 05 должна перехватываться клиентским приложением, которое и должно перезапускать транзакцию. Если все происходит как нужно, пользователь даже не заподозрит о том, что произошла взаимоблокировка.
Вместо того чтобы позволять самому серверу решать, какую из транзакций выбирать на роль “жертвы”, самой транзакции можно “сыграть в поддавки”. Следующий код, будучи помещенным в транзакцию, информирует SQL Server о том, что в случае возникновения взаимоблокировки данную транзакцию следует откатить:
SET DEADLOCKJPRIORITY LOW
Минимизация взаимоблокировок
Даже несмотря на то, что взаимоблокировки легко выявить и обработать, лучше все-таки их избегать. Приведенные ниже рекомендации помогут вам избежать взаимоблокировок.
Старайтесь делать транзакции короткими и не содержащими излишнего кода. Если некоторый код не обязательно должен присутствовать в транзакции, он должен быть выведен из нее.
Никогда не ставьте код транзакции в зависимость от ввода пользователя.
Старайтесь создавать пакеты и процедуры, устанавливающие блокировки, в одном и том же порядке. Например, вначале обрабатывается таблица А, затем таблицы Б, В и т.д. Таким образом, одна процедура будет ожидать второй и взаимоблокировки не смогут возникнуть по определению.
Планируйте физическую схему так, чтобы хранить одновременно отбираемые данные как можно ближе на страницах данных. Для этого используйте нормализацию и продуманно выбирайте кластеризованные индексы. Уменьшение разброса блокировок поможет избежать их эскалации. Небольшие блокировки помогут избежать их конкуренции.
Не увеличивайте уровень изоляции, если в этом нет необходимости. Более строгий уровень изоляции увеличивает продолжительность блокировок.
«» — это единая универсальная среда для доступа, настройки и администрирования всех компонентов MS SQL Server, а также для разработки компонентов системы, редактирования текстов запросов, создания скриптов и пр. Благодаря наличию большого количества визуальных средств управления, «Среда SQL Server Management Studio » позволяет выполнять множество типовых операций по администрированию MS SQL Server администраторам с любым уровнем знаний SQL Server. Удобная среда разработки, встроенный веб-браузер для быстрого обращения к библиотеке MSDN или получения справки в сети, подробный учебник, облегчающий освоение многих новых возможностей, встроенная справка от сообществ в Интернете и многое другое позволяют максимально облегчить процесс разработки в среде SQL Server, а также дает богатые возможности для создания различных сценариев SQL Server. Об установке и запуске программы «Среда SQL Server Management Studio » и пойдет речь в данной статье.
1. Установка программы «Среда SQL Server Management Studio»
Программа «Среда SQL Server Management Studio » поставляется вместе с дистрибутивом MS SQL Server. Для ее установки необходимо отметить компоненты
- Средства управления - основные (Management Tools - Basic)
- Средства управления - полный набор (Management Tools - Complete)
на странице выбора компонент программы установки MS SQL Server.

Подробно про установку компонент MS SQL Server я писал в статье .
2. Запуск программы «Среда SQL Server Management Studio»
По умолчанию файлы программы «SQL Server Management Studio » устанавливаются в «C:\Program Files (x86)\Microsoft SQL Server\110\Tools\Binn\Management Studio\». Для запуска «SQL Server Management Studio » следует запустить исходный файл Ssms.exe , находящийся в данной директории.
Также в Microsoft Windows Server 2012 (R2) ярлык для запуска «SQL Server Management Studio » можно найти в списке всех программ.

А в Microsoft Windows Server 2008 (R2) в меню «Пуск » (Start) — «Microsoft SQL Server 2012 » — «Среда SQL Server Management Studio ».

После запуска программа предложит ввести имя SQL сервера, к которому следует выполнить подключение, а также данные для авторизации на этом сервере. Строку соединения с сервером необходимо вводить в формате:
- <АдресСервера > — имя или IP адрес сервера для экземпляра по умолчанию
- <АдресСервера >\<ИмяЭкземпляра > — для именованного экземпляра SQL Server
- <ИмяПсевдонима > — если применяются SQL Server
В случае проверки подлинности Windows (Windows Authentication), используются данные текущей учетной записи Windows. Если необходимо использовать учетные данные другого пользователя, то необходимо и программу запустить . В случае использования проверки подлинности SQL Server (SQL Server Authentication), необходимо ввести имя пользователя и пароль существующего пользователя SQL Server.
Введя имя экземпляра сервера и данные для авторизация необходимо нажать «Соединить » (Connect) для подключения к выбранному SQL серверу.
