« . Сегодня поговорим о составлении семантического ядра, а также о подборе и анализе ключевых слов. Как всегда будем рады любым вопросам и с удовольствием ответим на них.
Продвижение сайта нужно начинать с составления семантического ядра, то есть подбора ключевых фраз, по которым нужно попасть в топ. После подбора ключей принимается решение о том, какие дополнительные разделы и страницы нужно добавить на сайт. Именно поэтому сначала проводится подбор слов, а только потом работа над внутренней оптимизацией сайта.
Тактика продвижения разных ключей может отличаться. Самые конкурентные фразы продвигают на главной странице, а иногда на нескольких внутренних. При этом особые усилия прикладывают к тому, чтобы страницы были удобными и обеспечивали высокую конверсию. А для сбора трафика по запросам с низкой конкуренцией нужно множество простых информационных страниц. Продвигать такие страницы на порядок легче.
Рекомендуется подобрать максимум ключевых фраз – чем больше ключей, тем выше трафик. К слову, SEO-компании начинают свою работу над сайтами клиентов с того, что значительно расширяют семантическое ядро (и правильно делают). Им важно добиться быстрого и ощутимого результата в виде прироста трафика. Самый простой и верный способ, который часто игнорируют вебмастера, – это как раз расширение списка продвигаемых ключевых фраз.
Почему желательно выделять десятки и сотни ключей, а не останавливаться на продвижении 5-10 важнейших запросов? Во-первых, продвижение по низкочастотным запросам гораздо проще и дешевле, а в сумме они обычно дают гораздо больший трафик, чем главные коммерческие запросы. Более того, не факт, что по мощным коммерческим запросам сразу удастся потеснить конкурентов. Скорее всего, по этим запросам уже идет ожесточенная борьба между оптимизаторами. Поэтому, чтобы не тратить деньги и силы впустую, нужно продвигать сразу большое количество разных ключей.
А еще самые популярные общие запросы, такие как «мебель», «газоны», «канцтовары» и прочие, мало пригодны для коммерческих целей. Цена продвижения таких запросов высока, а коммерческий эффект ничтожен. Поэтому гораздо лучше и дешевле продвигать, например, отдельные модели телевизоров, чем запрос «телевизоры».
Совет: если вы решили воспользоваться услугами SEO-компании, спросите у менеджера, по какому количеству ключей они обычно продвигают клиентов. Узкое семантическое ядро (до пары десятков ключей) должно вас насторожить. Это значит, потенциал продвижения используется не в полную силу.
Ну а теперь перейдем к подбору ключевых слов, используя разные инструменты.
Мозговой штурм
Так совпало, что на момент написания этого пособия по продвижению сайтов мы решили продвигать один из наших проектов, биржу текстов Копилансер . И поэтому лучше всего в качестве живого примера рассматривать именно его. Итак, начинаем мозговой штурм и определяем, какие ключи семантического ядра могут быть полезными при продвижении этого сайта, что именно может искать наша целевая аудитория в Яндексе и Гугле. Сходу удалось придумать совсем немного ключей, а именно:
- Биржа текстов
- Биржа копирайтинга
- Биржа копирайта
- Заказать текст
- Биржа контента
- Биржа статей
Этот список был бы гораздо длиннее, если бы мы продвигали интернет-магазин, так как в нем каждая товарная позиция является отдельным ключом. После того, как фантазия на этапе мозгового штурма исчерпана, обращаемся к помощи Яндекса и Гугла. Сначала мы посмотрим, как семантическое ядро разрабатывается вручную, а потом то, как можно автоматизировать эту работу при помощи платных программ.
Яндекс.Директ и Гугл Адвордс
3. При подборе ключевых слов в Яндексе и Гугле используйте кавычки для поиска по точному, а не широкому соответствию.
4. Старайтесь собрать как можно больше ключевых слов для семантического ядра, исключая ключи с самым низким трафиком (30 по Яндексу или 10 по Гуглу).
5. Исключите из семантического ядра ключи, которые никак не связаны с вашим сайтом,
под которые вы не готовы создавать отдельные информационные страницы.http://seo-case.com/ .
Предоставляем не просто группы фраз в excel с собранными частотностями, а целый комплекс информации на все случаи развития и продвижения сайта.
Банальные истины…….
Добрый день! В прошлый раз мы разбирались в том, . Если вы смогли для себя ответить на все поставленные в прошлой теме вопросы, то это значит, вы готовы идти дальше и в конечном итоге запустить свой интернет-проект, конечно же, с моей помощью 🙂
Итак, в этот раз мы узнаем, как составить семантическое ядро сайта правильно своими руками. На самом деле всё довольно просто, конечно, если речь не идёт о крупном информационном портале или интернет-магазине, однако я думаю, если вы новичок, то вы не будете браться сразу за глобальные проекты, а начнёте с малого.
Конечно, при составлении и проектировании семантики можно столкнуться с рядом проблем, для которых понадобятся другие программы. Узнайте, чем собрать семантическое ядро – большой каталог полезных программ.
Как правильно составить семантическое ядро сайта?
Проектирование семантического ядра в виде инфографики
Перед тем как перейти к подробному описанию процесса сбора семантики для сайта или блога, в 2018 году я решил дополнить статью инфографикой, где по пунктам перечислены все основные этапы проектирования СЯ.
Инфографика – это только краткий “пересказ” всех действий! Посмотреть инфографику и “всё осознать” не получится, необходимо прочитать статью, а лучше сделать это несколько раз и потом потренироваться на практике! Инфографика призвана подготовить вас к восприятию всей информации по созданию семантического ядра и предварительно разложить всё по полочкам.
А вот собственно и она:

Сбор СЯ для сайта в виде инфографики
В нормальном качестве можно открыть кликнув “Правой кнопкой мыши по картинке” –> “Открыть в Новой вкладке” или .
Как собрать семантическое ядро быстро с помощью KeyCollector’a или СловоЁБа? (UPD в 2017,2018 годах )
Итак, весь процесс будет состоять из нескольких пунктов:
- запускаем программу (неважно какую КейКоллектор или СловоЁБ, однако в KeyCollector есть возможность сбора Поисковых подсказок, что существенно расширяет СЯ);
- создаём проект;
- находим кнопки, которые изображены на скриншоте и в открывшиеся окна вбиваем наши фразы;
- ждём какое-то время, пока программа собирает ключи (можно смело идти пить чай 🙂);
- удаляем все не нужные нам запросы (купить, скачать, перечисление городов России и прочее);

- собираем частотность «!», т.е. только точные вхождения (в СловоЁБе это «Лупа», в КейКоллекторе буква «Д» обозначающая Яндекс.Директ);
- удаляем все нулевые запросы и запросы с частотностью 1 в месяц (UPD в 2017 я изменил подход и );
- UPD 10.2018 После того как мы пропарсили первый раз все ключевые слова и сняли частотку, берём ТОП-30-50 самых высокочастотных запросов и вновь начинаем парсить Wordstat и поисковые подсказки.
- UPD 10.2018 после повторного парсинга к имеющимся запросам необходимо добавить ключи из Букварикса и Keys.so, подробнее об этом я писал в , обязательно прочтите!
- после этого выгружаем всё в Excel и дальше начинаем работать там.
Разбираем семантическое ядро собранное программой
После работы программы мы получаем большое количество ключей, которые и называются семантическим ядром нашего сайта. Однако мало собрать ключи, их нужно грамотно рассортировать.
Для этого открываем Excel, сортируем всё по количеству запросов, начиная с высокочастотных.
Раз в качестве примера мы взяли Сиамских кошек, продолжим в том же духе.
Title для сайта
Из самых высокочастотных (ВЧ) запросов составляем Title нашего сайта, пытаясь задействовать как можно больше вхождений слов из соседних ВЧ-запросов. Например, «Сиамские кошки: содержание, кормление и размножение».
В Title сайта заложена сама суть всего ресурса, то чему он посвящён. Title должен включать в себя самые высокочастотные запросы, но скомбинированные в одну читаемую фразу . Нельзя просто взять и напихать все ВЧ-запросы подряд, как попало.
Например, если самые ВЧ-фразы это:
- Сиамские кошки.
- Кормление сиамских кошек.
- Сиамские кошки лечение.
То наш Title будет выглядеть примерно так: «Сиамские кошки: кормление и лечение». Таким образом, мы захватываем весь спектр запросов по всем трём фразам.
Важно! Нельзя разделять запросы точками, можно использовать запятые, двоеточие, тире, прямую линию, слэш, т.е. всё что угодно, но не точки.
Группируем семантику – создаём рубрики
Далее процесс проектирования семантического ядра заключается в том, что мы пытаемся составить группы из собранных ключей, например, для сиамских кошек они могут представлять собой: беременность сиамских кошек, чем кормить сиамских кошек, как содержать сиамских кошек и прочее. Я думаю, суть ясна.
Для того чтобы разбить на группы пользуемся Фильтрами в Excel, вбивая слова, например: «Кормление», после чего будут оставаться лишь фразы, в которые входит это слово. Фразы одной группы копируем на отдельный лист.
После разбиения всех слов на группы (они будут располагаться каждая на своём листе), мы получим так называемые Рубрики. Сразу хочу заметить, что процесс разбора семантического ядра на группы или как его ещё называют, кластеризация поисковых запросов, очень трудоёмкий, но от него зависит дальнейший успех вашего блога или сайта.
UPD 10.2018 Настоятельно рекомендую статью про кластеризацию (), т.к. начиная с 2018 года при проектировании, сборе и кластеризации семантического ядра я со своей командой начал практиковать новый подход при разгруппировки запросов. Новый подход сильно облегчает жизнь и ускоряет процесс.
Разбиваем Рубрики на статьи
После того как у нас получились Рубрики, например, «Кормление», «Содержание», «Размножение». По тому же принципу, используя фильтры в Excel, отбираем ключи для будущих статей.
Таким образом, у нас получатся рубрики, в которых будет по несколько статей, из которых и будет состоять ваш сайт про сиамских кошек.
Работа с ключами для статей
Когда вы полностью разберёте всё семантическое ядро по Рубрикам, а Рубрики по статьям, в самих статьях тоже необходимо будет навести порядок. Для этого самые частотные запросы, необходимо превратить в Title самих статей, по тому же принципу, как мы формировали Title сайта.
Определившись с Title, разбиваем ключи на те, которые просто будут встречаться в статье (частотность минимальная) и те, которые будут подзаголовками. Чем частотнее запрос попадёт в заголовок, тем больше вероятность, что статья соберёт по этому ключу трафик.
Важно! Не пихайте в подзаголовок точное вхождение ключа, если оно корявое, например, «сиамские кошки кормить чем», сделайте их «человеческими», даже если такой фразы нет в собранном вами семантическом ядре, всё равно подзаголовок выглядеть «Чем кормить сиамских кошек?». Это относится и к Title.
Семантическое ядро собрано!
Проделав все вышеописанные манипуляции, мы соберём семантическое ядро для своего сайта, что, во-первых, обеспечит нас запасом тем для статей на неопределённое количество времени, а, во-вторых, даст отличный толчок для продвижения, ведь правильно составленное семантическое ядро – это залог успешности вашего проекта !
Итак, надеюсь, я смог ответить на вопрос, как составить семантическое ядро сайта правильно своими руками, конечно же, используя программу KeyCollector или СловоЁБ.
Напоследок хочу дать совет, напишите для начала хотя бы по одной статье для каждой рубрики на вашем сайте, а ещё лучше напишите статей 50-100 сразу и поставьте их в очередь на публикацию. Это необходимо для того, чтобы в будущем вас не подгоняла необходимость написать статью в отведённый день, ведь писать статьи нужно в тот момент, когда посещает муза, а не делать это «из-под палки».
Дешёвый KeyCollector (UPD Неактуально 05.2018 )
Выше я сказал, что я могу дать скидку на покупку KeCollector в размере 10%, это так, переходите в и пишите письмо с темой «Скидка 10% на KeCollector» и я вам помогу 🙂 .
Кроме того, если у вас не получилось собрать семантическое ядро самостоятельно, то вы можете (это актуально 🙂).
Резюме
- Определяемся с тематикой.
- Пишем на листочке несколько слов/фраз относящихся к тематике и наиболее обширно описывающие её.
- Пользуемся программой KeCollector или СловоЁБ для сбора семантического ядра.
- Фильтруем и удаляем не нужные и нулевые запросы.
- Составляем Title сайта.
- Разбиваем ключевые слова на Рубрики.
- Разбиваем Рубрики на статьи.
- Структурируем статьи подзаголовками.
В следующей статье №2 я расскажу о том, .
Критикуйте статью, задавайте вопросы!
Как составить семантическое ядро сайта
Здравствуйте, уважаемые читатели блога. Данная статья написана в рамках марафона. Напомню, что мы учимся создавать сайты под РСЯ и зарабатывать на них. Присоединиться к нам можно в любой момент – все подробности в статьях по тегу «марафон». Ищите на блоге.
Как составить семантическое ядро сайта? Давайте разбираться
Как обычно, перед тем, как мы перейдем непосредственно к практике, мне хотелось бы высказать несколько теоретических мыслей, дать свое понимание этого вопроса.
Составлять семантическое ядро сайта не так сложно, как вы можете подумать. Это всего-навсего рутинная, «нудная» работа. Но никак не сложная, сверхсекретная.
Для успешной работы вы обязательно . Напомню, что там мы составили подразделы своего будущего сайта, причем сделали это максимально подробно.
Чем подробнее и качественнее выполнен предыдущий урок, тем легче вам будет справиться с этим. Если же там сделано 2-3 раздела – обязателньо уделите время тому материалу. Сейчас вы поймете, почему это важно.
Какие программы нужны для составления ядра?
Я пользуюсь всего лишь двумя программами/сервисами:
- Key collector;
- Сервис rooke.ru
При помощи Кей Коллектора мы парсим нужные ключевые слова, формируем группы этих слов для написании статей.
Сервисом руки мы анализируем конкурентов.
Мне вполне достаточно этих инструментов. Замечу, что платный Key collector вполне можно заменить программой Словоёб. Выбирайте сами, что использовать.
Key collector: работа с семантическим ядром
Признаться, я не представляю, как работал без этой программы ранее. Собственно, она за вас делает всю рутинную работу, вам же остается нажать несколько кнопок, отбросить мусор, скопировать отчет с хорошими кеями под статью. Давайте разбираться.
Я привык все показывать на примерах. Так оно сильно понятнее. Тем более, если это касается работы с программами/сервисами.
В предыдущем уроке мы рассматривали в качестве примера тематику «канализация». Далеко от нее отходить не будем и сейчас.
К примеру, нам нужно подобрать ключи под написание статей для этой части нашего ядра.

Нужно составить семантическое ядро раздела
Парсим это ключевое слово в кей коллекторе (обязательно собираем все виды частотностей).
Отчетливо видим группы запросов, именно под них мы и будем писать статьи в дальнейшем.

В данном случае это запрос «трос для прочистки канализации» , следующим основным запросом группы будет «прочистка засоров канализации» и так далее сверху-вниз.
Когда сделали парсинг, нужно отбросить «ключи-пустышки»: это те ключевые слова, точная частотность которых меньше либо равна «!5» (данный параметр зависит от трафика тематики, может быть увеличен или уменьшен). А также убираем ключи, явно не подходящие, под вашу статью (другие города, слова-амонимы и т.п).

Отбрасываем запросы-пустышки
Оставшиеся ключи сортируем по убыванию (вверху у нас находится самый частотный ключ группы).
Минутку внимания:)
Наверняка, Вам интересен дополнительный заработок в Интернете.
Предлагаю инструменты, которые несколько лет использую сам:
Сохраняем проект, экспортируем ключи в эксель файл. На основе их мы будем писать статью в дальнейшем.

Экспорт в Эксель
Я описал подробный процесс составления семантического ядра сайта, повторюсь, когда вы «набьете руку», соберете ни одну сотню запросов, можно парсить только более-менее частотные ключи, и на основании их сразу уже выписывать темы для статей, нужные ключевые сова для них. Но изначально лучше все делать, так как описано: подробно и пошагово.
Однако, для того, чтобы понять, как писать статью (какой объем, сколько раз повторять ключ и т.п.), нам мало знать ключевые запросы под нее, нужно еще проанализировать конкурентов.
Делаем это при помощи выше упомянутого сервиса rooke.ru.
Анализ конкурентов при помощи сервиса rooke.ru
Перед тем, как делать анализ, нам нужно установить необходимые настройки. Замечу, что система позволяет делать анализ конкурентов абсолютно бесплатно.

Начало создания РК в rookee
В поле адрес сайта указываем любой сайт: можно ваш блог, можно создаваемый сайт под РСЯ – разницы нет.
Затем нужно выбрать приоритетную поисковую систему. В нашем случае выбираем Яндекс, так как именно под эту поисковую систему мы делаем свой сайт, и продвигаться также будем под нее.

Процесс создания РК
Выберите и тематику сайта.

Выбираем нужное
Система прогнозирует бюджет на продвижение, считает количество посетителей.
Переходим в нашу рекламную компанию. Добавляем нужный запрос (проанализируем конкурентов на основании все тех же КС – «трос для прочистки канализации»). Не забудьте снять галочку, запустить продвижение по добавленным запросам.

Добавляем нужный запрос в систему
Запрос добавлен в систему, затем нам необходимо проанализировать конкурентов. Нажимаем на соответствующую кнопку.

Анализ конкурентов
Нам достаточно собирать следующие параметры (другие не рекомендую, так как будете терять время).

Какие настройки выставлять
Когда система сделала за вас всю работу (просмотрела конкурентов, все просчитала), она выведет результирующий файл.
Самым ленивым (надеюсь, что вы не такие) можно воспользоваться ей.
Из таблицы берем следующие данные: среднее количество символов текста, всего вхождений, точных вхождений.

Система сделала нужный нам анализ
Для тех, кто не боится потратить лишние 30-60 секунд (я это делаю): экспортируем таблицу в эксель, отсеиваем два результата с максимальным объемом символов, и два с минимальным.
На основании шести оставшихся результатов анализируем те же показатели: объем статьи, количество вхождений. Тем самым мы получаем более объективные и реальные данные.

Экспортируем таблицу с конкурентами
Собственно, на этом анализ конкурентов закончен.
У нас есть все данные для составления технического задания на написание статьи копирайтером (ее объем, количество вхождений «основного ключа», НЧ ключи достаточно будет употребить 1 раз).
Как правильно составить семантическое ядро?
Я описал свой опыт составления семантического ядра. Считаю, что он правильный, ибо приносит результаты: трафик на сайт.
Если вкратце описать процессы, можно сказать, что правильный сбор семантического ядра заключается в следующем:
- Парсим выдачу;
- Отсеиваем не нужные, «пустые» запросы;
- На основании наиболее частотного ключа из синонимической группы запросов анализируем конкурентов;
- Собираем все данные в один файл (это и есть ваше ядро);
- Получаем исходные данные для написания статьи.
Да, не спорю, вам может показаться, что это слишком сложная задача, она будет «забирать» очень много времени, вы не справитесь…
До скорой встречи.
UPD : если Вам лень самим все это делать: вникать в нюансы, покупать Кей Коллектор, то можно заказать семантическое ядро у Вадима Захарова по приятным ценам . Знаю Вадима уже много лет, успешно сотрудничаем все это время.
Если вам знакома боль от «нелюбви» поисковиков к страницам вашего интернет-магазина, прочитайте эту статью. Я расскажу о пути к повышению видимости сайта, а точнее, о его первом этапе — сборе ключевых слов и составлении семантического ядра . Об алгоритме его создания и инструментах, которые при этом используются.
Зачем составлять семантическое ядро?
Для повышения видимости страниц сайта. Cделать так, чтобы поисковые роботы Яндекса и Google начали находить по запросам пользователей страницы именно вашего сайта. Безусловно, сбор ключевых слов (составление семантики) — первый шаг к этой цели. Дальше набрасывается условный «скелет» для распределения ключевых слов по разным посадочным страницам. А затем уже пишутся и внедряются статьи/метатеги.
Кстати, на просторах интернета можно найти множество определений семантического ядра.
1. «Семантическое ядро — упорядоченный набор поисковых слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товар или услугу, предлагаемые сайтом». Википедия .
Для сбора семантики конкурентов в Serpstat введите один из ключевых запросов, выберите регион, нажмите «Поиск» и перейдите в категорию «Анализ ключевых фраз». Затем выберите «SEO-анализ» и нажмите «Подбор фраз». Экспортируйте результаты:

2.3. Используем Key Collector/Словоёб для создания семантического ядра
Если нужно составить семантическое ядро для крупного интернет-магазина, без Key Collector не обойтись. Но если вы новичок, то удобней использовать бесплатный инструмент — Словоёб (пусть это название вас не пугает). Скачайте программу, а в настройках Яндекс.Директ укажите логин и пароль от своей Яндекс.Почты:  Создайте новый проект. Во вкладке «Данные» выберите функцию «Добавить фразы». Выберите регион и введите запросы, которые вы получили ранее:
Создайте новый проект. Во вкладке «Данные» выберите функцию «Добавить фразы». Выберите регион и введите запросы, которые вы получили ранее:  Совет: создавайте отдельный проект под каждый новый домен, а под каждую категорию/посадочную страницу делайте отдельную группу. Например:
Совет: создавайте отдельный проект под каждый новый домен, а под каждую категорию/посадочную страницу делайте отдельную группу. Например:  Теперь соберите семантику из Яндекс.Вордстата. Откройте вкладку «Сбор данных» — «Пакетный сбор слов из левой колонки Yandex.Wordstat». В открывшемся окошке выберите галочку «Не добавлять фразы, если они уже есть в любых других группах». Впишите несколько самых популярных среди пользователей (высокочастотных) фраз и нажмите «Начать сбор»:
Теперь соберите семантику из Яндекс.Вордстата. Откройте вкладку «Сбор данных» — «Пакетный сбор слов из левой колонки Yandex.Wordstat». В открывшемся окошке выберите галочку «Не добавлять фразы, если они уже есть в любых других группах». Впишите несколько самых популярных среди пользователей (высокочастотных) фраз и нажмите «Начать сбор»: 
Кстати, для больших проектов в Key Collector можно собрать статистику из сервисов анализа конкурентов SEMrush, SpyWords, Serpstat (ex. Prodvigator) и других дополнительных источников.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его
вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :

Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:

Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
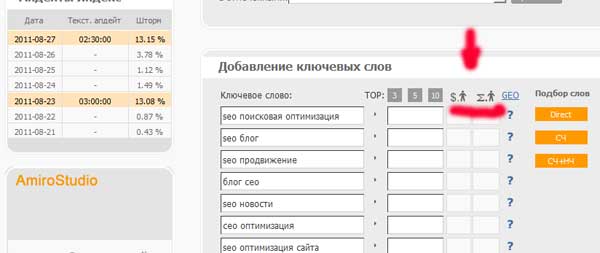
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:


Затем проверяем стоимость получения одного перехода по нашим ключевым словам:
Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.

Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника