Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия (в Excel 2007 этот режим находится в блоке Данные/Анализ данных/Регрессия). Затем полученные результаты скопировать в блок для анализа.

Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Количество уволившихся | Зарплата |
||
30000 рублей |
|||
35000 рублей |
|||
40000 рублей |
|||
45000 рублей |
|||
50000 рублей |
|||
55000 рублей |
|||
60000 рублей |
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а 0 + а 1 x 1 +…+а k x k , где х i — влияющие переменные, a i — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Множественная регрессия
Под таким термином понимается уравнение связи с несколькими независимыми переменными вида:
y=f(x 1 +x 2 +…x m) + ε, где y — это результативный признак (зависимая переменная), а x 1 , x 2 , …x m — это признаки-факторы (независимые переменные).
Оценка параметров
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже)

Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой

Отсюда получаем:

где σ — это дисперсия соответствующего признака, отраженного в индексе.
МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение:

в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1.
Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi.
Задача с использованием уравнения линейной регрессии
Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т.
номер месяца | название месяца | цена товара N |
|
1750 рублей за тонну |
|||
1755 рублей за тонну |
|||
1767 рублей за тонну |
|||
1760 рублей за тонну |
|||
1770 рублей за тонну |
|||
1790 рублей за тонну |
|||
1810 рублей за тонну |
|||
1840 рублей за тонну |
|||
Для решения этой задачи в табличном процессоре «Эксель» требуется задействовать уже известный по представленному выше примеру инструмент «Анализ данных». Далее выбирают раздел «Регрессия» и задают параметры. Нужно помнить, что в поле «Входной интервал Y» должен вводиться диапазон значений для зависимой переменной (в данном случае цены на товар в конкретные месяцы года), а в «Входной интервал X» — для независимой (номер месяца). Подтверждаем действия нажатием «Ok». На новом листе (если так было указано) получаем данные для регрессии.
Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде:
Цена на товар N = 11,714* номер месяца + 1727,54.
или в алгебраических обозначениях
y = 11,714 x + 1727,54
Анализ результатов
Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно.
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
(критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:

- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.

Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Известна тем, что она полезна в разных областях деятельности, включая и такую дисциплину, как эконометрика, где в работе используется данная программная утилита. В основном все действия практических и лабораторных занятий выполняют в Excel, которая существенно облегчает работу, давая подробные объяснения тех или иных действий. Так, один из инструментов анализа «Регрессия» применяется с целью подбора графика для набора наблюдений за счет метода наименьших квадратов. Рассмотрим, что представляет собой данный инструмент программы и в чем заключается его польза для пользователей. Ниже также предоставлена краткая, но понятная инструкция построения регрессионной модели.
Основные задачи и виды регрессии
Регрессия представляет собой зависимость между заданными переменными, за счет чего можно определить прогноз будущего поведения данных переменных. Переменные — это различные периодические явления, включая и поведение человека. Такой анализ программы Excel применяется для того, чтобы проанализировать воздействие на конкретную зависимую переменную значений одной или некоторым количеством переменных. К примеру, на продажи в магазине влияет несколько факторов, включая ассортимент, цены и место локализации магазина. Благодаря регрессии в Excel можно определять степень влияния каждого из указанных факторов по результатам имеющихся продаж, а после применить полученные данные для прогнозирования продаж на другой месяц или для другого магазина, расположенного рядом.
Обычно регрессия представлена в виде простого уравнения, раскрывающего зависимости и силу связи между двумя группами переменных, где одна группа является зависимой или эндогенной, а другая — независимой или экзогенной. При наличии группы взаимосвязанных показателей зависимая переменная Y определяется исходя из логики рассуждений, а остальные выступают в роли независимых Х-переменных.
Основные задачи построения регрессионной модели заключаются в следующем:
- Отбор значимых независимых переменных (Х1, Х2, …, Xk).
- Выбор вида функции.
- Построение оценок для коэффициентов.
- Построение доверительных интервалов и функции регрессии.
- Проверка значимости вычисленных оценок и построенного уравнения регрессии.
Регрессионный анализ бывает нескольких видов:
- парный (1 зависимая и 1 независимая переменные);
- множественный (несколько независимых переменных).
Уравнения регрессии бывает двух видов:
- Линейные, иллюстрирующие строгую линейную связь между переменными.
- Нелинейные — уравнения, которые могут включать степени, дроби и тригонометрические функции.
Инструкция построения модели
Чтобы выполнить заданное построение в Excel, необходимо следовать указаниям:

Для дальнейшего вычисления следует использоваться функцию «Линейн ()», указывая Значения Y, Значения Х, Конст и статистику. После этого определите множество точек на линии регрессии с помощью функции «Тенденция» — Значения Y, Значения Х, Новые значения, Конст. При помощи заданных параметров вычислите неизвестное значение коэффициентов, опираясь на заданные условия поставленной задачи.
На мой взгляд, как студента, эконометрика – это одна из самых прикладных наук из всех, с которыми мне удалось познакомиться в стенах своего университета. С помощью неё, действительно, можно решать задачи прикладного характера в масштабах предприятия. Насколько эффективными будут эти решения – вопрос третий. Суть в том, что большая часть знаний так и останется теорией, а вот эконометрика и регрессионный анализ всё-таки стоит изучить с особым вниманием.
Что объясняет регрессия?
Прежде, чем мы приступим к рассмотрению функций MS Excel, позволяющих, решать данные задачи, хотелось бы вам на пальцах объяснить, что, в сущности, предполагает регрессионный анализ. Так вам проще будет сдавать экзамен, а самое главное, интересней изучать предмет.
Будем надеяться, вы знакомы с понятием функции из математики. Функция – это взаимосвязь двух переменных. При изменении одной переменной что-то происходит с другой. Изменяем X, меняется и Y, соответственно. Функциями описываются различные законы. Зная функцию, мы можем подставлять произвольные значения X и смотреть на то, как при этом изменится Y.
Это имеет большое значение, поскольку регрессия – это попытка объяснить с помощью определённой функции на первый взгляд бессистемные и хаотичные процессы. Так, например, можно выявить взаимосвязь курса доллара и безработицы в России.
Если данную закономерность обнаружить удастся, то по полученной нами в ходе расчетов функции, мы сможем составить прогноз, какой будет уровень безработицы при N-ом курсе доллара по отношению к рублю.
Данная взаимосвязь будет называться корреляцией. Регрессионный анализ предполагает расчет коэффициента корреляции, который объяснит тесноту связи между рассматриваемыми нами переменными (курсом доллара и числом рабочих мест).
Данный коэффициент может быть положительным и отрицательным. Его значения находятся в пределах от -1 до 1. Соответственно, мы может наблюдать высокую отрицательную или положительную корреляцию. Если она положительная, то за увеличением курса доллара последует и появление новых рабочих мест. Если она отрицательная, значит, за увеличением курса, последует уменьшение рабочих мест.
Регрессия бывает нескольких видов. Она может быть линейной, параболической, степенной, экспоненциальной и т.д. Выбор модели мы делаем в зависимости от того, какая регрессия будет соответствовать конкретно нашему случаю, какая модель будет максимально близка к нашей корреляции. Рассмотрим это на примере задачи и решим её в MS Excel.
Линейная регрессия в MS Excel
Для решения задач линейной регрессии вам понадобится функционал «Анализ данных». Он может быть не включен у вас поэтому его нужно активировать.
- Жмём на кнопку «Файл»;
- Выбираем пункт «Параметры»;
- Жмём по предпоследней вкладке «Надстройки» с левой стороны;

- Снизу увидим Надпись «Управление» и кнопку «Перейти». Жмём по ней;
- Ставим галочку на «Пакет анализа»;
- Жмём «ок».

Пример задачи
Функция пакетного анализа активирована. Решим следующую задачу. У нас есть выборка данных за несколько лет о числе ЧП на территории предприятия и количестве трудоустроенных работников. Нам необходимо выявить взаимосвязь между этими двумя переменными. Есть объясняющая переменная X – это число рабочих и объясняемая переменная – Y – это число чрезвычайных происшествий. Распределим исходные данные в два столбца.

Перейдём во вкладку «данные» и выберем «Анализ данных»
В появившемся списке выбираем «Регрессия». Во входных интервалах Y и X выбираем соответствующие значения.
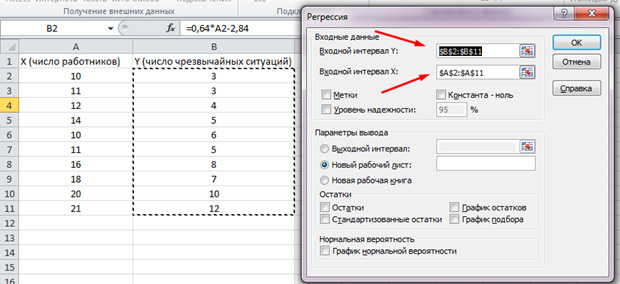
Нажимаем «Ок». Анализ произведён, и в новом листе мы увидим результаты.
Наиболее существенные для нас значения отмечены на рисунке ниже.
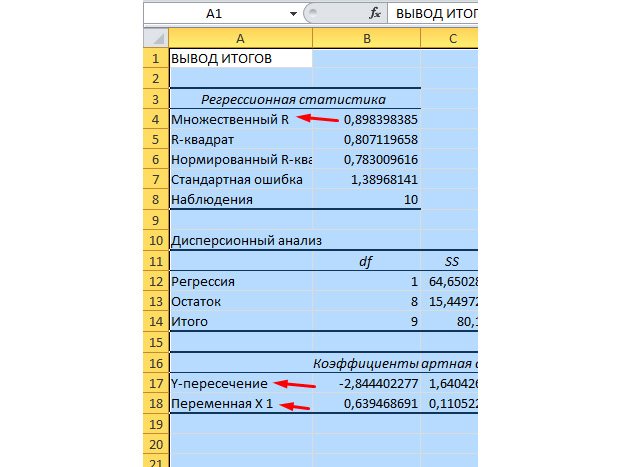
Множественный R – это коэффициент детерминации. Он имеет сложную формулу расчета и показывает, насколько можно доверять нашему коэффициенту корреляции. Соответственно, чем больше это значение, тем больше доверия, тем удачнее наша модель в целом.
Y-пересечение и Пересечение X1 – это коэффициенты нашей регрессии. Как уже было сказано, регрессия – это функция, и у неё есть определённые коэффициенты. Таким образом, наша функция будет иметь вид: Y = 0,64*X-2,84.
Что нам это даёт? Это даёт нам возможность составить прогноз. Допустим, мы хотим нанять на предприятие 25 работников и нам нужно примерно представить, каким при этом будет количество чрезвычайных происшествий. Подставляем в нашу функцию данное значение и получаем результат Y = 0,64 * 25 – 2,84. Примерно 13 ЧП у нас будет происходить.
Посмотрим, как это работает. Взгляните на рисунок ниже. В полученную нами функцию подставлены фактические значения по вовлеченным работникам. Посмотрите, как близки значения к реальным игрекам.

Вы так же можете построить поле корреляции, выделив область игреков и иксов, нажав на вкладку «вставку» и выбрав точечную диаграмму.

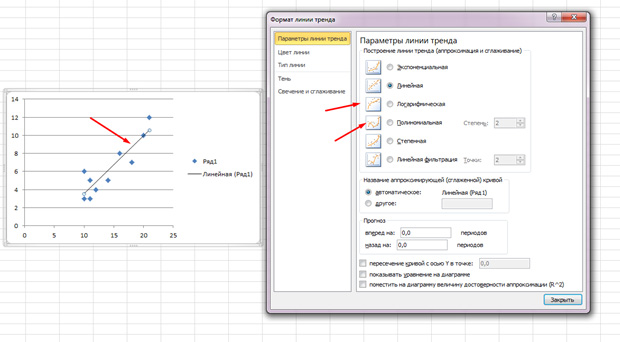
Точки идут вразброс, но в целом двигаются вверх, как будто посередине лежит прямая линия. И эту линию вы так же можете добавить, перейдя во вкладку «Макет» в MS Excel и выбрав пункт «Линия тренда»
Щелкните дважды по появившейся линии и увидите то, о чем говорилось ранее. Вы можете изменять тип регрессии в зависимости от того, как выглядит ваше поле корреляции.
Возможно, вам покажется, что точки рисуют параболу, а не прямую линию и вам целесообразней выбрать другой тип регрессии.
Заключение
Будем надеяться, что данная статья дала вам большее понимание о том, что такое регрессионный анализ и для чего он нужен. Всё это имеет большое прикладное значение.
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.
Модель линейной регрессии имеет следующий вид:
У = а 0 + а 1 х 1 +…+а к х к.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:


После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.


В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» - первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» - второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:



Теперь стали видны и данные регрессионного анализа.